
Last month, Claude told one of our customers their pipeline was on track. They were missing their target by 21%. Nine deals hadn't been touched in 30 days. A live customer had cancelled their payment method. A Slack thread flagged a competitor displacement, but nobody updated the CRM.
Claude reported none of it.
This isn't a story about AI being wrong. It's a story about what confident, incomplete answers cost a revenue team that needs to build the infrastructure to support them.
Yes, Claude Cowork is genuinely useful. It connects to your CRM, automates pipeline reports, and answers revenue questions in plain language. The productivity gains are real. But Claude doesn't verify. It reasons, and it reasons on whatever you give it. The data can be clean or dirty, complete or missing, reconciled or contradictory.
Claude doesn't say "I'm not sure." It says "here's your weekly pipeline summary", and it's wrong in a way that looks exactly like being right.
The blind spots of Claude Cowork and MCP: Why a CRM connection isn’t enough
Model Context Protocol, or MCP, is the connector layer that gives Claude access to your CRM. It hands Claude whatever your reps entered. That includes what they skipped, mislabelled, and forgot. It's a pipe, and a good one. The context gap unfolds because the connection (or pipe) doesn't clean what flows through it.
Here's what HubSpot MCP does give Claude:
- Deal records as they exist today, not how they actually progressed
- Activity logs, to the extent reps logged them
- Stage data, including stages nobody updated when the deal went cold
Here's what HubSpot MCP doesn't give Claude:
It doesn't share what your numbers mean
What's an SQL in your business? How do you calculate NRR? What counts as churn versus a downgrade? HubSpot doesn't encode these. Neither does Claude. So it makes its best guess confidently, and without flagging the ambiguity.
It doesn't share if you're on track
Claude can pull your closed-won total. It has no idea what your number is, which motion is supposed to carry it, or whether your current pace puts you ahead or behind. A number without a target isn't a signal. It's noise.
It doesn't share what's happening outside your CRM
Your CRM says the deal is active. Your call recording platform has a transcript where the prospect's leadership called budget a "huge challenge." Your billing platform shows a payment bounce on a live account. A Slack thread between your AE and their manager says the champion just left. Claude, via HubSpot MCP, sees none of this.
It doesn't share where decisions actually get made
Half the decisions that shape a deal happen in Slack. That means the data isn’t attached to a single source of truth. None of it reaches the CRM, including; escalations, pricing approvals, competitive intel, a CSM flagging renewal risk. Claude can't reason about what it can't see.
It doesn't give reasoning to question what it's given
Claude treats all data as ground truth. That includes skipped stages, stale deals, missing close dates. It has no way to know otherwise.
This is what a revenue data layer built specifically for RevOps solves. And without it, silent pipeline decay ensues.
3 ways Claude Cowork failed our customer’s pipeline review
Let’s dig into what happened to our customer last month. They’re a B2B SaaS company, mid-seven-figure ARR, 38 active accounts, running on HubSpot. We’ve anonymised the examples below, but the numbers are real.
Failure #1: No targets loaded
Claude had no pipeline target context
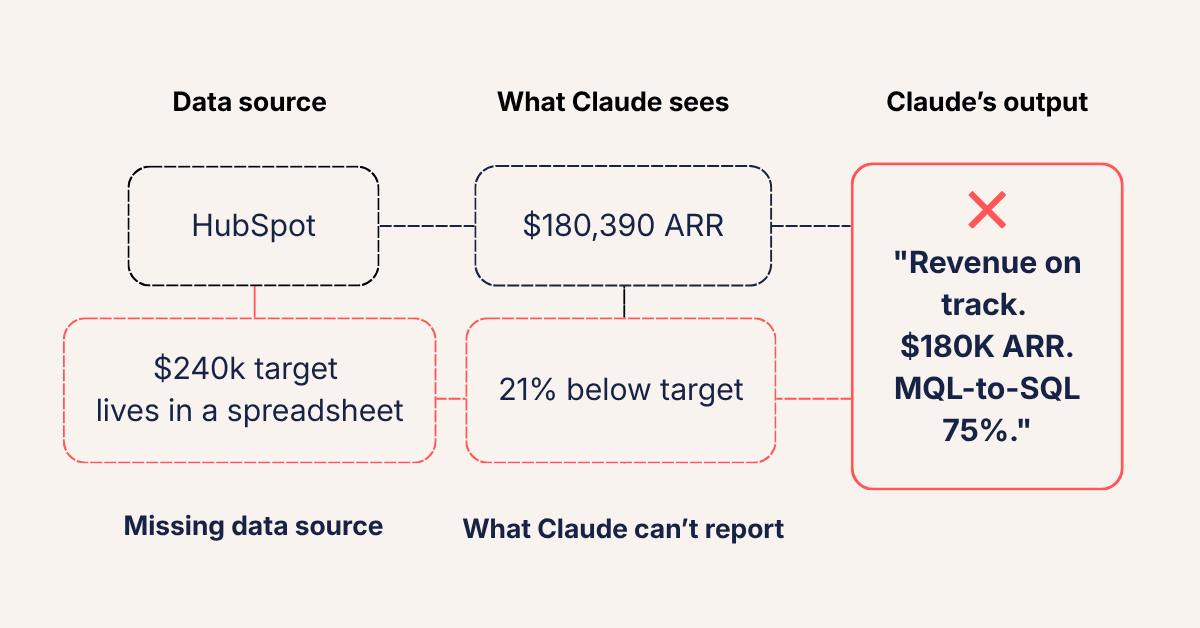
The team had a number: $240,000 for the quarter. It lived in a spreadsheet, updated by the RevOps lead every 90 days.
Claude had never seen it. So when it looked at $180,390 in closed-won ARR and a pipeline that appeared to be moving, it had no frame of reference to tell the difference between on track and 21% behind.
It reported progress. The team heard confidence. Nobody questioned it because the output looked exactly like outputs they'd acted on before.
Two numbers told completely different stories:
- $180,390 new ARR against a $240,000 target, which is a 21% miss. The CRM couldn't surface this because it didn't know the target. Claude reported the number. Nobody told it what the number meant.
- 34% SQL-to-SAL conversion. The funnel was bottlenecked at qualification. Claude reported the MQL-to-SQL number — 75% — because that's what HubSpot tracks cleanly. The conversion rate that actually mattered was invisible to it.
By the time someone ran the numbers manually, two weeks of pipeline calls had already been run on the wrong assumption.
Failure #2: No one governing the data
Claude trusted what it was given
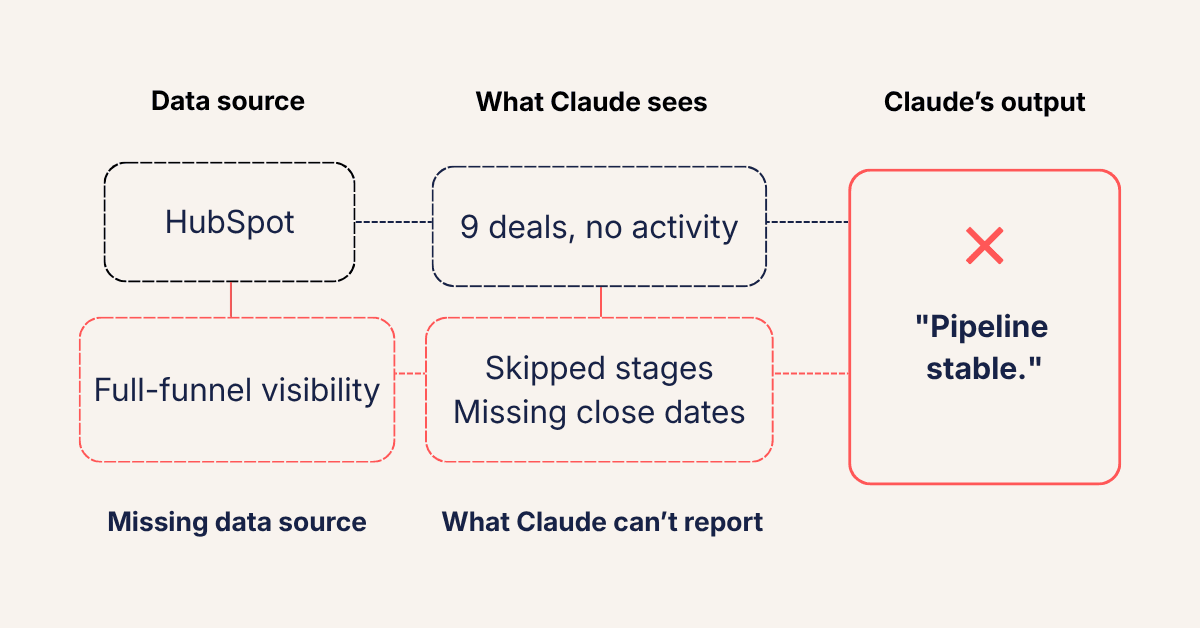
Nine deals in their pipeline hadn't been touched in over a month. This includes no calls logged, emails sent, or stage changes. The reps were unsure about the truth, suspecting these deals were cold.
Closing them out means admitting a loss, and nobody had been prompted to do it. So they watched as HubSpot and Claude counted further away from accuracy.
The pipeline looked fuller than it was because the data said it was, and Claude had no way to ask whether the data was telling the truth.
One deal bucket summed it up:
- 9 deals with zero engagement for 30+ days. No calls. No emails. No stage changes. HubSpot still showed them as active because no rep had closed them out. Claude reported them as part of a healthy pipeline.
It’s a phantom pipeline, where deals that look like opportunities have no real pulse.
Failure #3: No bridge between systems
Claude couldn’t see outside the CRM
This is where the story gets costly. While Claude was reporting a stable week, the data it was missing would have changed every conversation in that pipeline review.
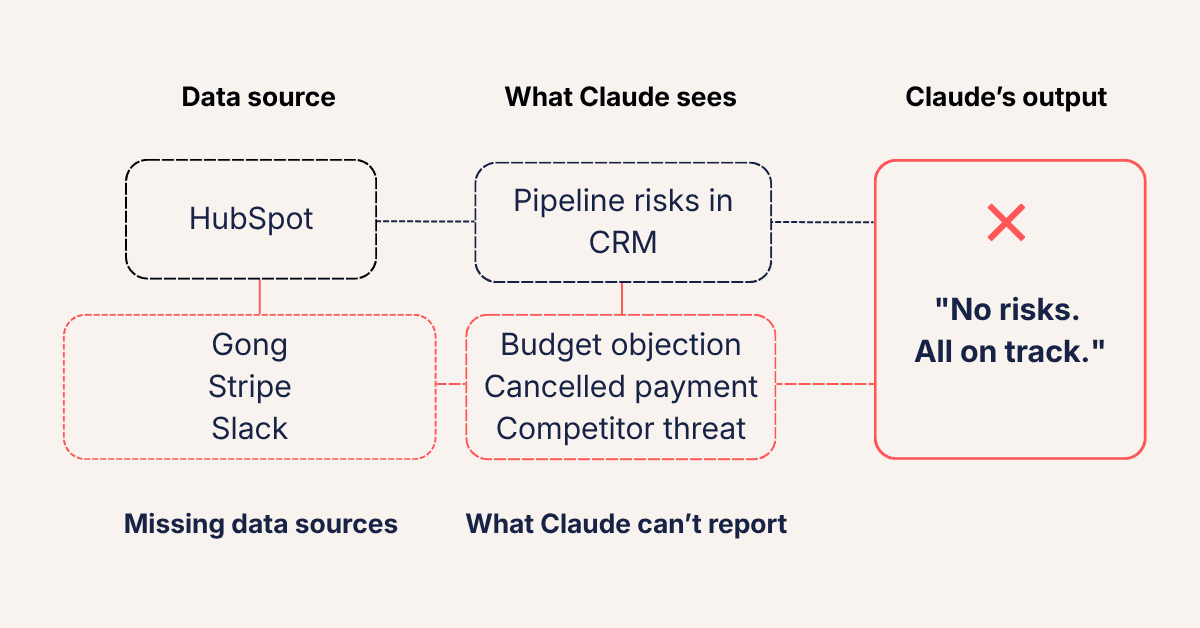
Three risks were hiding in plain sight:
- Norden had cancelled their payment method and closed their bank account. The billing event was in Stripe. The CRM showed a healthy account. Claude never saw it.
- Kepler's leadership flagged budget as a "huge challenge" on a recorded sales call. The deal was still progressing in the CRM as if that conversation had never happened.
- A Slack thread between the AE and Sales Director flagged a competitor displacement at Meridian. The AE had written "they're evaluating [Competitor X], we need to move fast." Nobody updated the deal record. Claude reported Meridian as on track.
Three active risks, including a churning customer, a stalling deal, a competitive threat, were left unflagged. Why? Because the signals lived in systems Claude couldn't see.
Now multiply that first output by every report, every one-on-one prep, every territory review, every board update. The confidence compounds. The inaccuracy compounds with it.
The solution: A revenue data layer built for RevOps
The three failures above share a single problem: Claude had no structured foundation to reason across. No shared definitions, no plan context, no cross-system connections. It made its best guess every time, and the best guess looked exactly like the right answer.
The opportunity is straightforward. Build a revenue data layer: a structured, clean representation of how your business actually works, built specifically for AI to reason on. Every agent you deploy gets a single trustworthy version of your revenue reality. Not a data warehouse. Not another CRM field. Three connected layers that together close the gap.
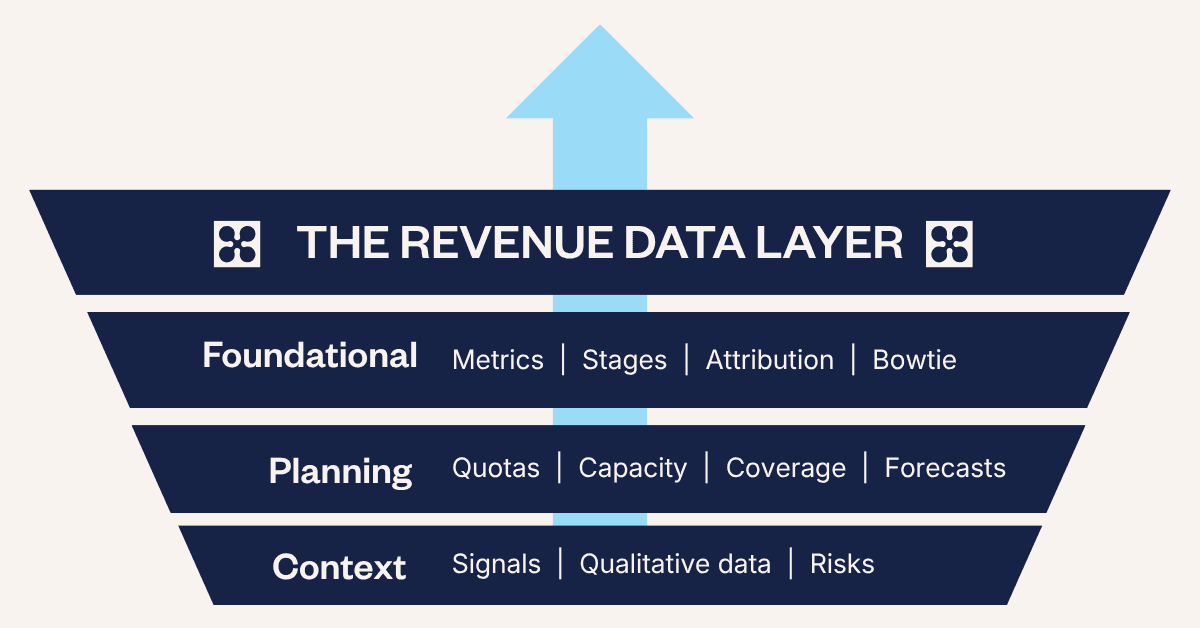
Layer 1: Foundational | Your business map
This is your ICP tiers, lifecycle stages, channel definitions, and revenue taxonomy. Your foundational layer tells Claude what an SQL means in your business, which motion is supposed to carry the number, and how your funnel is supposed to flow. Without it, Claude reverse-engineers a plausible answer every time you ask it a question.
Layer 2: Planning | Precise numbers
The planning layer includes targets by rep, quota by motion, benchmarks by segment. This is what turned $180,390 from a neutral observation into a 21% miss. Without a planning layer, Claude has no target to compare against, and reports the number as on-track.
Layer 3: Context graph | The connective tissue
With a context graph, deal histories, call transcripts, billing events, and Slack threads become connected, sequenced, and traceable to source. This is what would have surfaced Norden's cancellation, Kepler's budget objection, and the Meridian competitor threat before they became invisible risks in a confident report.
As Guillaume, Vasco's CEO, puts it:
"If you don't have that data layer for AI to reason on, it's going to reverse-engineer a plausible answer every single time you ask it a question. At any company size, that doesn't get you to a production-ready RevOps stack."
The good news is you don't need to build this from scratch. The right platform gives RevOps teams the structured revenue data layer out of the box.
That means you'll be ready to connect agents that run on top of your business's unique pre-configured definitions, lifecycle stages, and revenue taxonomy.
It’s an AI context gap, not a Claude Cowork gap
Same Claude, different data layer.
The AI context gap is a readiness problem, and it shows up in every AI workflow deployed before the foundation is in place. Claude didn't reveal a flaw in the tool. It revealed where most RevOps stacks actually stand.
Getting Claude Cowork right starts with establishing a revenue data layer underneath it, by employing a revenue context graph that gives Claude a single, trustworthy version of reality to reason across. Get that right and the outputs will drive outcomes.


